

Ciao a tutti, oggi parleremo di Text Mining, una procedura comunemente utilizzata in vari ambiti per estrarre informazioni da dati pubblicati in forma non strutturata (es articoli di giornale, libri, tweet, ecc.).
Gli algoritmi presenti nei software al giorno d’oggi sono in grado di estrarre e classificare le informazioni presenti nei testi in maniera molto efficiente e affidabile.
Del resto, i metodi qualitativi a disposizione dell’essere umano (lettura e sintesi del testo) sono poco efficienti e non sono in grado di individuare spesso correlazioni o informazioni latenti.
In questo post, e in una serie di post successivi, vi illustrerò alcune funzionalità di base del software R applicabili al Text Mining.
Faremo inoltre riferimento alle librerie del “tidyverse”, che rendono le procedure di pre-processamento ed elaborazioni dei dati più semplici anche per i neofiti.
R e il tidyverse
R al giorno d’oggi è un ambiente di programmazione open source molto diffuso compatibile con MAC, WINDOWS e LINUX.
È nato nei primi anni novanta per applicazioni statistiche, come alternativa al linguaggio rilasciato con licenza commerciale S.
Io cominciai ad utilizzarlo parecchi anni fa per superare alcune limitazione della mia licenza MATLAB.
Oggi utilizzo per vari scopi entrambi i linguaggi anche se il mio povero core i3 comincia ad avere problemi a digerire il pesante runtime di MATLAB.
Da questo punto di vista R può venirvi in soccorso anche se avete un PC un po’ datato.
Lo strumento che vi consiglio per lo sviluppo dei vostri progetti è RStudio.
RStudio è un ambiente di sviluppo integrato pensato per il data science ed è riduttivo considerarlo esclusivamente un’IDE per R.
A seguire alcuni dei suoi punti di forza:
- I pythonisti utilizzando la sintassi RMarkdown potranno apprezzare molte similitudini con i notebook e i kernel python.
- La sintassi RMarkdown supporta la coesistenza nello stesso documento di script in altri linguaggi di programmazione (es. Python, shell scripts, JavaScript, CSS, ecc.).
- Attraverso il motore Pandoc possiamo pubblicare i risultati delle nostre ricerche nei formati più diffusi (html, pdf, docx, epub, LaTex, ecc.)
- Possiamo creare App e Dashboard interattive con Shiny
Sebbene l’ambiente R può girare anche su processori a 32 bit, le ultime versioni di RStudio sono compatibili solo con architetture a 64 bit.
Per l’installazione di R ed RStudio rimando il lettore alle numerose guide disponibili in rete.
Cos’è il tidyverse
Tidyverse è quello che in ambiente Linux definiremmo un meta-pacchetto: nel caso specifico possiamo installare in blocco una serie completa di librerie progettate in modo specifico per il data science.
Pertanto per installare tidyverse da console di RStudio inseriamo il seguente input:
install.packages("tidyverse")
Per gli amanti del pinguino premetto che i tempi di installazione possono essere un po’ lunghi visto che i pacchetti di solito vengono generati per compilazione dai sorgenti.
Eventuali error code in fase di installazione potrebbero dipendere dalla mancanza di alcune librerie di sistema che vanno installate esternamente dal package manager della distribuzione Linux.
Di seguito alcune peculiarità di tidyverse:
- Le funzioni sono progettate per operare direttamente sui vettori, l’uso dei cicli è quindi ridotto a casi specifici.
- Il suffisso str_ è presente in tutte le funzioni che operano sui vettori di stringhe.
- L’operatore %>% è una ‘pipe’. Valorizza l’argomento della funzione a destra dell’operatore con l’output della funzione che la precede. Con questo operatore possono essere concatenate diverse funzioni.
Risorse disponibili
Di seguito alcuni link utili di approfondimento degli argomenti trattati:
-
- The Comprehensive R Archive Network: il repository principale del software R
- Sociospunti e Ricerca sociale con R: preziosissimo materiale divulgativo interamente in italiano
- Text Mining with R: contenuti dell’omonimo libro rilasciati sotto creative commons
- Getting started with prodigenr: un Project Workflow che ci aiuta a strutturare bene i nostri progetti
- Presentation Ninja: esempio di utilizzo della libreria xaringan per la creazione di presentazioni
- Epubr: una libreria per estrarre contenuti e meta dati dagli ebook.
- The hunspell package: High-Performance Stemmer, Tokenizer, and Spell Checker for R
Giochiamo un po’ con le parole
Nei paragrafi successivi utilizzeremo come fonte testuale il libro “40 Novelle” di Hans Christian Andersen.
L’e-book lo possiamo scaricare gratuitamente dal portale Liber Liber al seguente link: https://www.liberliber.it/mediateca/libri/a/andersen/40_novelle/epub/andersen_40_novelle.epub
Lo scopo del nostro progetto è quello di estrarre dall’e-book le 40 Novelle che lo costituiscono e, dopo averne scelta una a caso, dare una rappresentazione statistica delle parole più significative estratte dal testo.
Nota: Liber Liber è una mediateca liberamente accessibile grazie a donazioni e partnership e al contributo di volontari che prestano la loro opera gratuitamente.
Template del progetto
Questo passaggio è opzionale, anche se personalmente ve lo raccomando.
Un progetto ben strutturato a mio avviso deve suddividere in cartelle distinte le varie sezioni che lo compongono, quali ad esempio: dati grezzi, dati elaborati, codice sorgente, sezione documentale per report e presentazioni.
La libreria prodigenr è uno dei tanti tool disponibili per questo scopo.
Questi tipi di tools permettono di creare lo scheletro del progetto e utilizzare dei comodi template per documentare la nostra ricerca (es. Xaringan, Distill).
L’installazione e l’utilizzo di base di questa libreria è ben documentata nel link riportato nella sezione precedente, l’help di RStudio è inoltre molto esaustivo.
L’approfondimento sull’uso di prodingenr esula dallo scopo di questo post, a titolo di esempio vi mostro un paio di immagini di una slide editata con xaringan e una pagina di report prodotta con Distill.

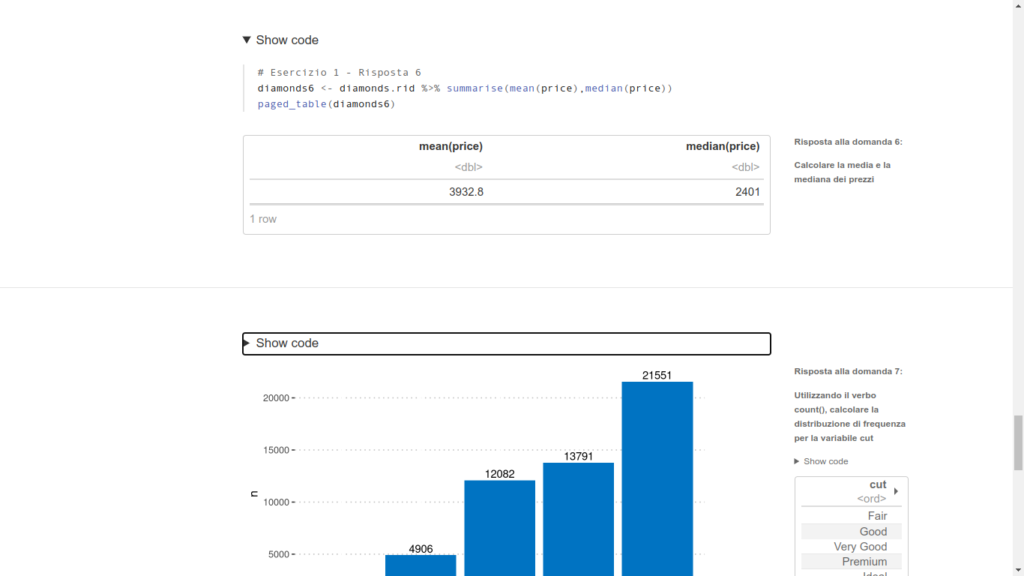
Detto questo, procediamo oltre, e iniziamo a creare il nostro progetto in RStudio.
Installazione dei pacchetti necessari
Il set minimale di librerie richieste per i nostri scopi è rappresentato da hunspell, stopwords, epubr.
install.packages(c("tidyverse","epubr","hunspell","stopwords"))
L’istruzione inserita su console di RStudio scaricherà e installerà i pacchetti in elenco con le relative dipendenze.
Per hunspell gli utenti Linux dovranno aver già installato su sistema le librerie relative (vedi link sopra riferito a hunspell package), rimando il lettore alla guida della propria distribuzione.
Estrazione dei contenuti e dei meta dati
Per una trattazione più dettagliata del formato epub e cenni sul software Sigil vi rimando ad un mio precedente contributo pubblicato sul blog CALIBRE OPDS SU DEBIAN.
Di seguito un elenco di operazioni propedeutiche alla scrittura del codice:
- Assumeremo di voler scaricare l’e-book utilizzando R.
- Creeremo in RStudio un nuovo progetto con il templare prodigenr.
- Utilizzeremo la directory di progetto data-raw per salvare l’e-book.
- La directory data-raw conterrà anche il file ‘elencoCapitoli.txt‘ di cui a seguire spiegheremo lo scopo.
- Nella directory di progetto R creeremo lo script EpubHelper.R dove salveremo tutto il codice del progetto.
- Nella directory di progetto data creeremo due sottocartelle Text ed Error (questo lo facciamo a mano per non complicarci troppo la vita, anche se potremmo farlo inserendo qualche istruzione in più nello script).
Download dell’e-book
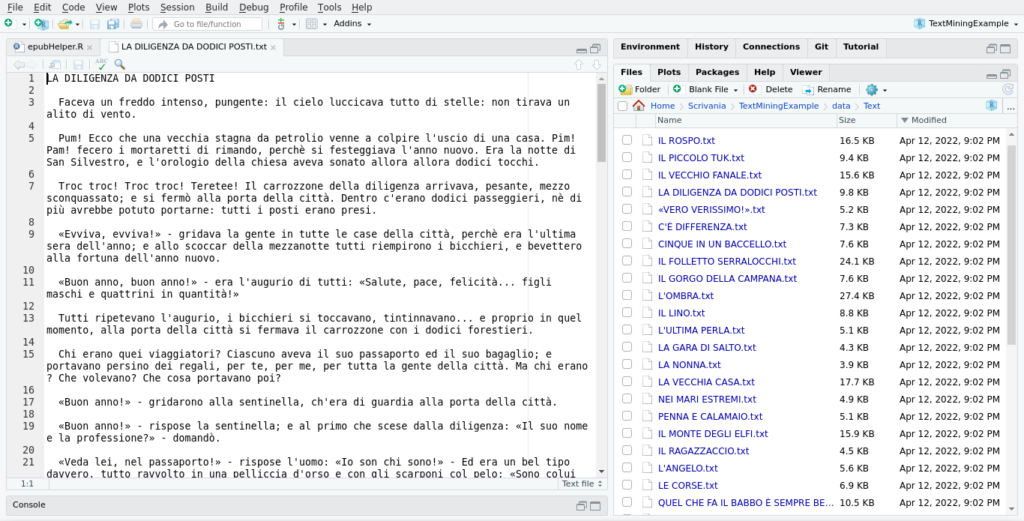
Creiamo nella directory R del nostro progetto uno script e salviamolo come EpubHelper.R.
Inseriamo nello script le seguenti righe di codice utili ad inizializzare alcune variabili d’ambiente e a creare la funzione per il download dell’e-book.
library(epubr)
library(tidyverse)
library(hunspell)
library(stopwords)
.GlobalEnv$url <- 'https://www.liberliber.it/mediateca/libri/a/andersen/40_novelle/epub/andersen_40_novelle.epub'
.GlobalEnv$outPath <- 'data-raw/example.epub'
.GlobalEnv$chListFilePath <- 'data-raw/elencoCapitoli.txt'
.GlobalEnv$Fiaba <- 'data/Text/'
.GlobalEnv$ErrorPath <- 'data/Error/'
### download dell'epub
getEpub <- function (){
system.file(download.file(url,outPath),package = "epubr")
}
Note a margine del codice:
- La funzione library() carica le librerie richieste dallo script. Assumiamo che le librerie siano già state installate, lascio come esercizio al lettore la possibilità di inserire nello script una procedura per l’installazione automatica dei pacchetti mancanti.
- In R noterete che l’operatore di assegnazione predefinito di variabili e funzioni è <- anche se il classico = viene comunque interpretato correttamente.
- In R le righe di codice non terminano con un end o un ; come in altri linguaggi.
- Le stringhe sono racchiuse da apice singolo o doppio apice.
- .GlobalEnv$ seguita dal nome della variabile crea variabili d’ambiente (o globali). La funzione getEpub() non ha infatti argomenti ma internamente può richiamare le variabili globali già inizializzate.
- La funzione getEpub() scarica il file dal percorso remoto url e lo salva nella cartella data-raw con il nome example.epub
Eseguiamo lo script:
- Salviamo lo script e clicchiamo sull’icona
sourcepresente sul riquadro dell’editor. - Noterete che nel task Environ visibile nel quadrante in alto a destra di RStudio sono ora presenti i Values riferiti alle variabili globali e sotto Functions il riferimento a getEpub()
- Se digitiamo ora sulla console l’istruzione getEpub() e navighiamo nella cartella data-raw dovremmo ritrovarci il file example.epub. La funzione ha scaricato il file dalla posizione remota e l’ha salvato nella directory di destinazione.
Titoli delle novelle
Premetto che ho scelto volutamente un e-book in cui le sezioni che lo compongono non rappresentano le diverse parti del testo.
Non esistono inoltre all’interno del testo delle parole chiave che permettono di individuare i diversi capitoli/novelle facilmente.
Ricordo al lettore che un file e-pub è costituito fondamentalmente da un archivio zippato contenente la struttura e i contenuti del libro.
La sfida è stata quindi quella di sfruttare le funzionalità della libreria epubr per estrarre i testi di tutte le 40 novelle che costituiscono il libro.
Prima di scrivere il codice vero e proprio analizziamo la struttura dell’e-book servendoci dell’editor Sigil.
Con questo strumento possiamo verificare che le 40 novelle sono contenute interamente nei file ‘Section0007.xhtml‘ e ‘Section0008.xhtml‘.
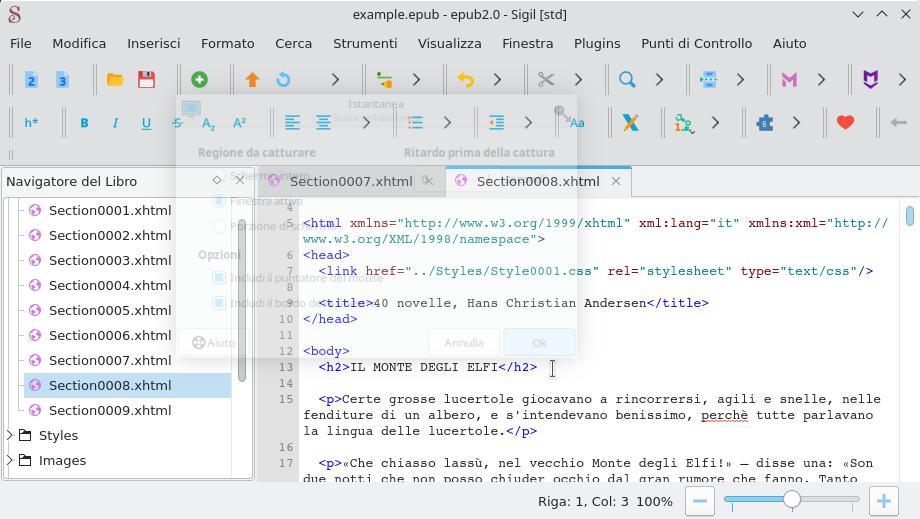
Altra cosa che ci permette di notare Sigil è che tutti i titoli delle novelle sono scritti in stampatello e sono racchiusi all’interno dei tag <h2></h2>, ovvero sono tutti titoli di livello 2.
La soluzione al nostro problema consiste nel creare la lista dei titoli delle novelle importarla nel nostro progetto e sfruttarla successivamente per manipolare il testo.
Per non impazzire a scrivervela tutta a mano, se avete dimestichezza con il software Sigil, potete crearvela velocemente con un piccolo trucco:
- Create con Sigil la tavola dei contenuti in formato html (menu Strumenti > Tavola dei Contenuti (TOC) > Genera Tavola dei Contenuti (TOC) in HTML).
- Aprite il file TOC.xhtml appena creato con l’editor visuale integrato PageEdit.
- Copiate l’elenco delle 40 novelle e incollatelo in nuovo file elencoCapitoli.txt salvandolo nella directory di progetto data-raw.
L’alternativa per sviluppatori seri è invece quella di unzippare il file epub ed estrarre i nodi che hanno link ai file ‘Section0007.xhtml’ e ‘Section0008.xhtml’ dal file in fomato xml toc.ncx (table of contents).
Estrazione del testo
Ora che abbiamo creato le risorse necessarie al nostro progetto aggiungiamo allo script epubHelper.R una nuova funzione che chiameremo EstraiNovelle().
A seguire il codice della funzione:
### Funzione per estrarre il testo dall'epub
estraiNovelle <- function (){
x <- epub(outPath, drop_sections = "Section000[1234569].xhtml",
chapter_pattern="^Section00\\d\\d")
elencoCapitoli <- read.delim(chListFilePath,header = FALSE) %>% unlist()
pat <- paste('(',paste(elencoCapitoli,collapse = "|"),')',sep='')
x <- x %>% epub_recombine(pattern = pat)
novelle <- x$data[[1]] %>% filter(substr(section,1,2) == "ch")
saveRDS(epub_meta(outPath),'data/metadata.rds')
for(i in 1:x$nchap){
fileName <- paste(Fiaba,elencoCapitoli[i],".txt",sep="")
fileConn <- file(fileName) writeLines(novelle$text[i] %>% unlist(),fileName)
close(fileConn)
return(elencoCapitoli)
}
Note a margine del codice:
La funzione una volta utilizzata creerà all’interno cartella del progetto data/Text 40 file di testo contenenti le novelle di Andersen, il nome di ciascun file corrisponde al titolo della novella con estensione .txt.
- creiamo con la funzione epub() della libreria epubr un oggetto x che contiene l’e-book (testi metadati, ecc.). Abbiamo passato alla funzione i seguenti argomenti:
- outPath: ovvero la variabile globale con il percorso ‘data-raw/example.epub’
- drop_sections: con un’espressione regolare indichiamo le sezioni da escludere dall’oggetto x (solo la 7 e la 8 sono quelle buone)
- chapter_pattern: con una espressione regolare il programma indica che i capitoli del libro hanno il prefisso ‘Section00’
- elencoCapitoli: vettore che ha per elementi i 4o titoli delle Novelle di Andersen creato dal file elencoCapitoli.txt.
- pat: stringa con espressione regolare che passeremo come argomento alla funzione epub_recombine.
- epub_recombine(): l’oggetto x contiene inizialmente l’e-book suddiviso in 2 sole sezioni. La funzione epub_recombine è in grado in base al pattern fornito di ristrutturare i data dell’oggetto x nel numero corretto di sezioni/novelle.
- novelle: l’oggetto x è in realtà costituito da una struttura dati di tipo lista. In R questo tipo di oggetto può contenere a sua volta strutture dati di tipo diverso. Facendola semplice, x$data[[1]] è una tabella di 2 colonne che contiene nella prima il nome assegnato al capitolo (es. ch01) e nella seconda colonna tutto il testo della novella. Il filtro ‘ch’ mi permette di eliminare le righe che non contengono capitoli del libro. La tabella filtrata la salviamo nella variabile novelle.
- saveRDS(): salva un tibble come file. Il tibble è una tabella dati, in questo caso abbiamo estratto con la funzione epub_meta una tabella con i metadati del libro.
- for(i in 1:x$nchap): questo ciclo salva ricorsivamente i file di testo delle novelle nella cartella data/Text.
- Nella funzione abbiamo inserito come valore di ritorno il vettore con la lista di capitoli che può tornaci utile in seguito per selezionare il testo da sottoporre ad analisi.
Lo script sopra riportato non è ovviamente nella sua forma finale, ma è solo una bozza del progetto R che sto sviluppando nei pochi ritagli di tempo.
Anteprima dei contenuti delle prossime puntate
Premetto che in origine avevo pensato di esaurire l’argomento in una sola puntata limitandomi ad introdurre alcuni concetti di base e senza entrare troppo in dettaglio.
Il 26 maggio 2022 ho presentato in sede, durante la serata “Web & Coding” l’ambiente RStudio e ho notato un certo interesse da parte di altri soci nel voler approfondire l’utilizzo di questo strumento per il TextMining.
Per non esaurire subito tutte le cartucce, ho quindi preferito diluire l’argomento introducendolo nelle serate di dibattito con gli altri soci e avvalendomi quindi anche del loro contributo.
Per quanto riguarda le “pillole” delle prossime puntate affronteremo sostanzialmente argomenti abbastanza semplici quali:
- Tokenizzazione del testo (libreria “hunspell”)
- Ricerca degli errori (libreria “hunspell”) e successiva correzione del testo
- Eliminazione delle stopwords (libreria “stopwords”)
- Distribuzione di frequenza delle parole e rappresentazione grafica in forma di word-cloud (libreria “wordcloud2”)
- Semplice analisi del sentiment e sui rappresentazione grafica in coordinate polari (libreria “ggplot”)
Augurandomi di aver acceso un briciolo di interesse in coloro che hanno seguito questo post, è doveroso a questo punto salutare tutti i lettori e i soci che seguono il blog.
Probabilmente più che al TextMining in questo momento starete già pensando a cosa mettere in valigia per quest’estate.


