

Ciao a tutti i lettori di OpenLinux, in questo post parleremo di web scraping.
Possiamo descrivere il web scraping in modo semplice e approssimativo come un insieme di tecniche di programmazione utili ad estrarre informazioni dalla pagine web.
Il web scraping nasce con il world wide web in quanto sistema primariamente impiegato dai motori di ricerca per indicizzare i siti internet.
Sotto questo ombrello possiamo metterci diverse famiglie di applicazioni scritte nei più disparati linguaggi, fra cui ad esempio:
- semplici programmi di DOM Parsing, come quello che vi presenterò a breve
- sistemi automatici di scansione della rete (spiderbot, crawler, ecc.) associati eventualmente ad algoritmi di classificazione e machine learning
Una trattazione più dettagliata di questo argomento la trovate nell’elenco dei link che è mia abitudine riportarvi.
In questo post vi mostrerò un esempio pratico di utilizzo di alcune librerie del linguaggio R già viste in PILLOLE DI TEXT MINING CON R (puntata 1).
Nello specifico vi illustrerò come eseguire il ‘DOM Parsing’ di un portale (librerie xml2 ed rvest) e come progettare il front-end dell’applicazione con Shiny.
")
Risorse e link utili
A seguire un elenco non esaustivo di link a risorse utili e alla documentazione delle librerie software utilizzate:
- https://it.wikipedia.org/wiki/Web_scraping
- Document Object Model
- https://cran.r-project.org/web/packages/xml2/index.html
- https://cran.r-project.org/web/packages/rvest/index.html
- https://www.tidyverse.org/
- https://www.tidyverse.org/
- https://shiny.rstudio.com/
- https://it.wikipedia.org/wiki/RSS
- https://getbootstrap.com/
Obiettivo dell’Analisi
Il sito oggetto dell’analisi è LiberLiber, un portale che permette l’accesso gratuito ad oltre 4000 opere letterarie in formato e-book e non più soggette a diritti d’autore.
L’applicazione dovrà essere in grado di fornire le seguenti funzionalità di ricerca:
- Elencare tutti gli autori che cominciano con una determinata iniziale;
- Dato il nome dell’Autore fornire il link alla relativa pagina e cercare l’elenco dei titoli disponibili;
- Noto il titolo del libro fornire un link per lo scaricamento degli e-book in formato epub se disponibile;
Nella seguente GIF animata un esempio di funzionamento dell’applicativo che ho sviluppato.
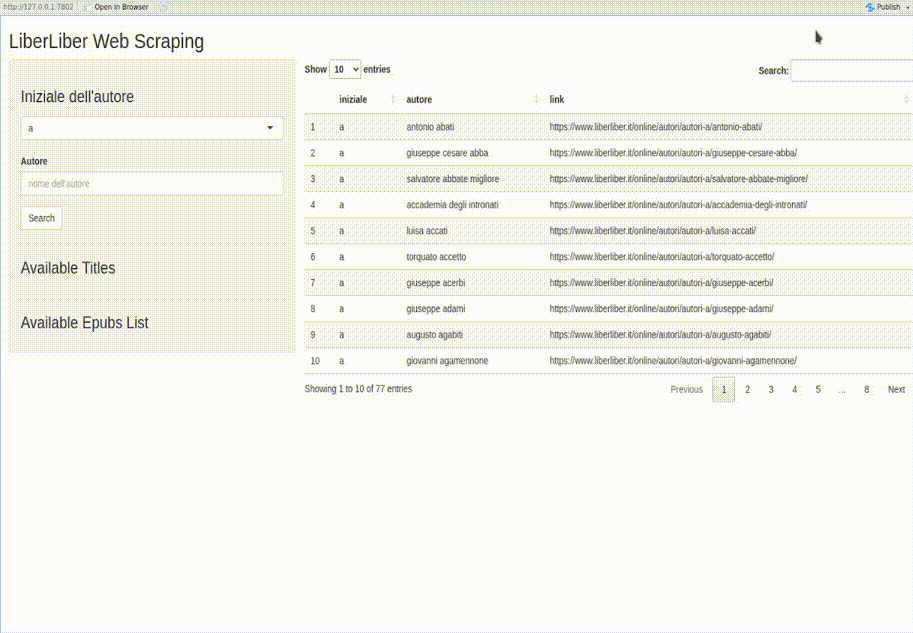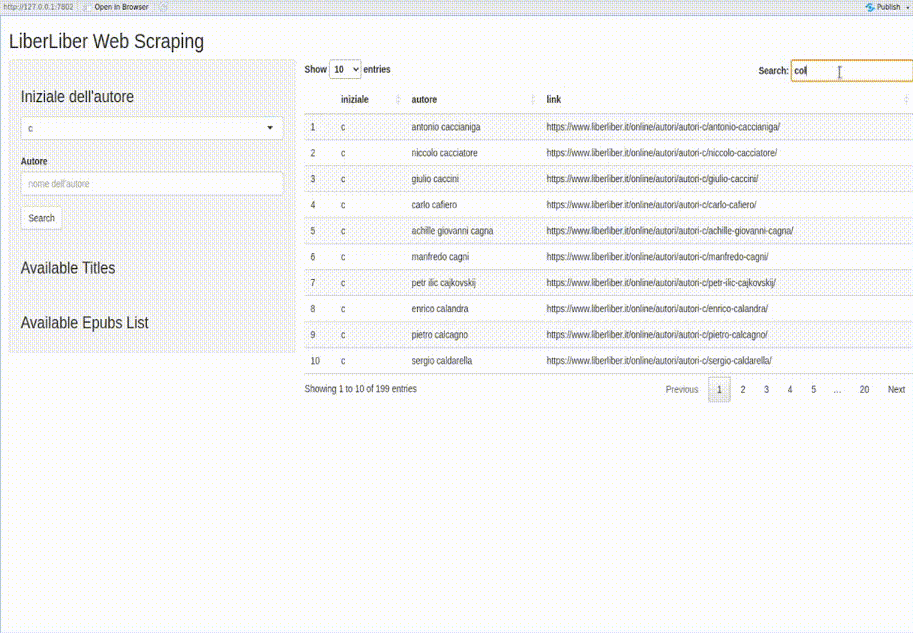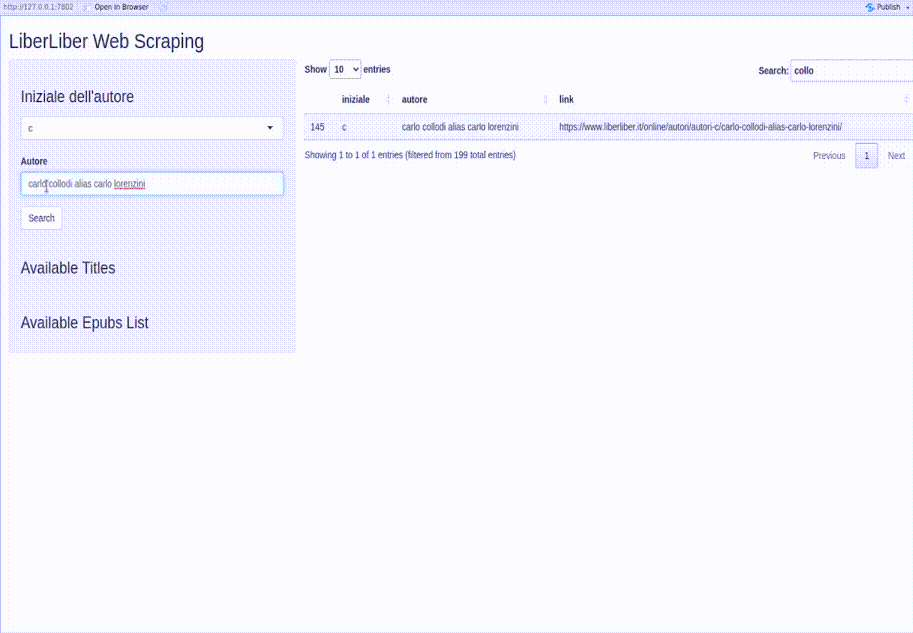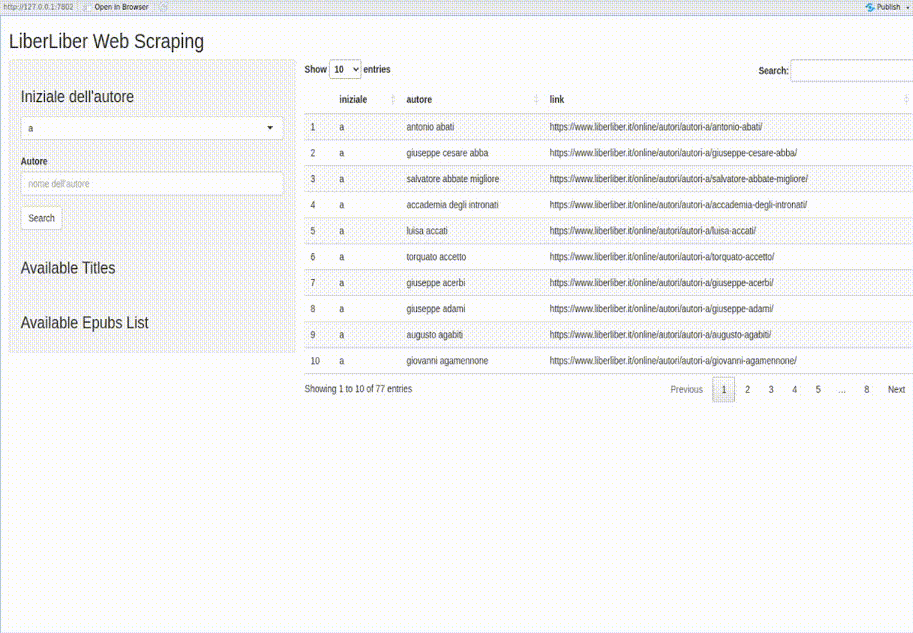
Analisi del problema
Scorrendo velocemente le pagine del portale LiberLiber noterete la presenza di numerosi banner e popup pubblicitari, molto fastidiosi e invadenti, che hanno presumibilmente lo scopo di finanziare gli oneri del progetto.
Per nostra fortuna i link delle diverse pagine web sono “parlanti” in quanto strutturati come i permalink standard di WordPress.
Questo è un comportamento tipico e prevedibile dei CMS con cui al giorno d’oggi sono progettati gran parte dei siti web.
Considerando ad esempio la pagina il cui URL termina con “autori-a”, ci aspettiamo di trovare nei contenuti di questa pagina tutti i link alle pagine degli autori che cominciano con la lettera “a” (es. ../autori-a/antonio-abati/).
Nello stesso modo le pagine formattate con i link degli autori conterranno in modo diretto o indiretto anche i link utili per raggiungere altre pagine che contengono per esempio i meta-dati e le risorse delle opere appartenenti ad un determinato autore.
L’idea è stata quindi quella di partire dall’URL ‘https://www.liberliber.it/online/autori/’ e salvare in forma tabellare i link alle pagine più interne, eliminando il rumore di fondo costituito da link ripetuti e da altri ink non non utili ai nostri scopi.
In questo modo è in teoria possibile scansionare e scaricare le risorse dell’intero portale mediante un ciclo o una funzione ricorsiva su tutti i link da ‘a’ a ‘z’.
Da un punto di vista etico ed economico non la ritengo una trovata geniale: impegnereste il vostro PC presumibilmente per diverse ore visto le migliaia di pagine da processore, mentre con una donazione di pochi euro a LiberLiber vi scaricare l’intero archivio in qualche minuto.
Altro approccio creativo sarebbe stato quello di sfruttare, se raggiungibili, eventuali feed.rss o altri file di mappatura in formato xml, implementati dal CMS per finalità di SEO o aggiornamento automatico del sito.
Implementazione del codice di Back-End dell’applicazione
A parte vari inciampi di percorso sono riuscito con meno di 90 righe a produrre uno script funzionante correggendo alcune “trappole” volute o involontariamente presenti nella struttura del sito.
Vi aggiungo a seguire e a titolo di esempio uno script del codice delle prime due funzioni di back-end e lo screenshot dell’ambiente di sviluppo RStudio che rappresenta graficamente gli oggetti generati dallo script (Data, Values e Functions).
Lo script completo eviterò di pubblicarlo in quanto non è mia intenzione mettere in difficoltà gli amici di LiberLiber.
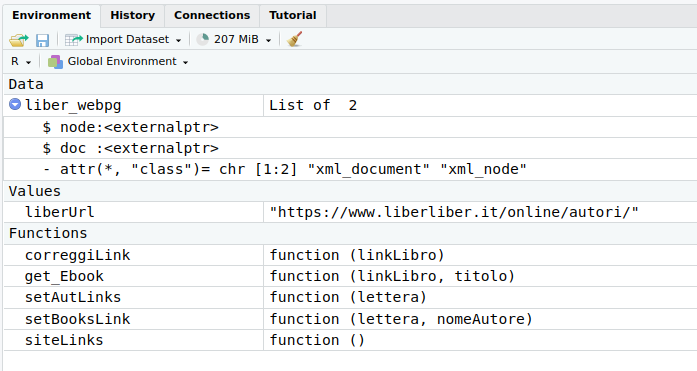
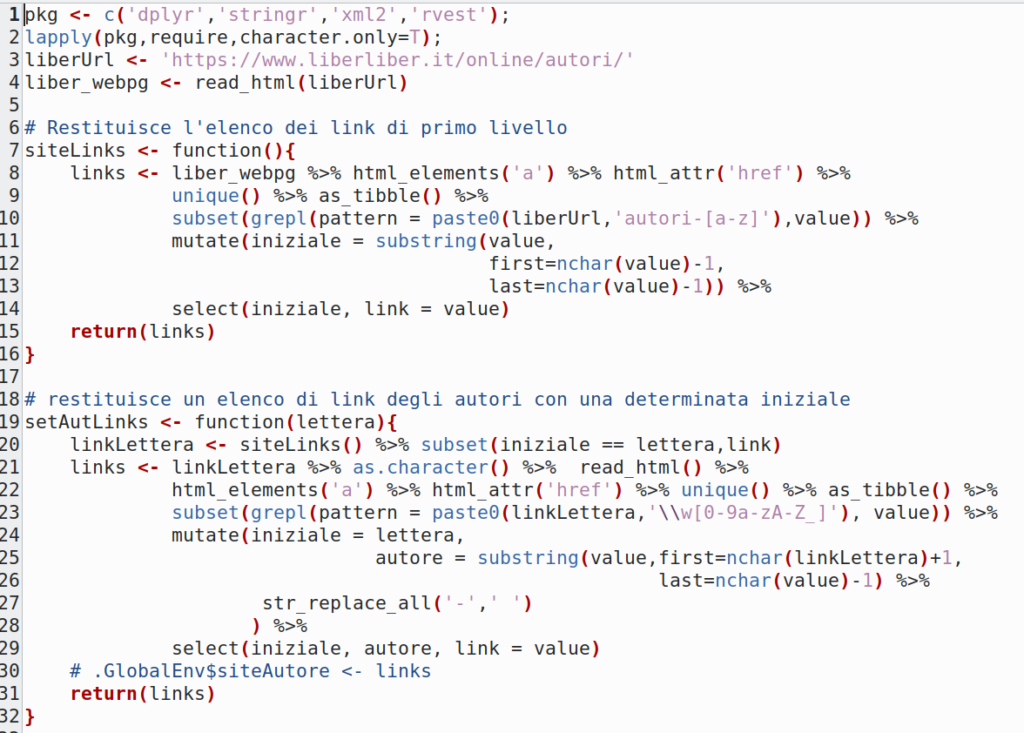
Commenti al codice dello script:
- La funzione
require()innestata in un ciclolapply()verifica la presenza delle librerie necessarie ed eventualmente ne esegue l’installazione; - LiberUrl è la risorsa ‘radice’ da cui far partire il DOM Parsing;
- L’oggetto
liber_wepggenerato con la funzioneread_html()rappresenta il Document Object Model della pagina ‘https://www.liberliber.it/online/autori/’ . - In R il modello viene implementato come lista di due oggetti di classe xml_document e xml_node;
- Tutti i Child o Elements della classe xml_node rappresentano i tag innestati a vari livelli nel documento come biforcazioni originate da una stessa radice;
- A partire dalla radice del DOM è possibile mediante l’operatore di pipe
%>%scorrere gerarchicamente gli elementi contenuti nel documento e ‘marcati’ con il tag<a>(vedi funzionehtml_elements('a')); - Gli attributi href dei tag
<a>contenenti le stringhe con i link alle altre pagine vengono estratti con la funzionehtml_attr('href'); - Le funzioni utilizzate successivamente a cascata dell’operatore
%>%hanno lo scopo di eliminare i link ripetuti, filtrarli in modo logico e a salvarli in formato tabellare (struttura dati di tipo tibble). In particolare le espressioni regolari passate come argomento alla funzionegrepl()permettono il riconoscimento dei pattern dei soli link validi.
Implementazione del codice del Front-End (Shiny)
Shiny è un pacchetto per R integrato nell’ambiente di sviluppo RStudio che permette in modo rapido di progettare applicazioni web interattive.
Un’applicazione Shiny viene generalmente avviata con l’istruzione shinyApp(ui = ui, server = server) o più semplicemente cliccando sul tasto run dell’ambiente di sviluppo
Il codice una volta eseguito avvia in localhost un server embedded messo in ascolto su una porta libera e non in conflitto con altri servizi (es. http://127.0.0.1:6980).
Il codice in alternativa può essere pubblicato ed eseguito su uno Shiny-Server installato localmente sulla stessa macchina oppure su server in cloud.
È immediato intuire che all’attributo ui della funzione shinyApp() è associato un oggetto che rappresenta l’interfaccia grafica (client), mentre all’attributo server è associato un oggetto che rappresenta le componenti lato server di elaborazione logica delle richieste del client.
Le due componenti, a seconda del gusto dello sviluppatore, possono essere incluse nello stesso script oppure separate in due file diversi.
La soluzione da me adottata prevede l’inclusione delle componenti dell’applicazione nello stesso script come da codice sotto riportato:

Commenti al codice dello script:
- Lo script che vi ho mostrato sopra per essere eseguito correttamente dovrà includere all’inizio del file anche le seguenti righe di codice:
- library(shiny): carico la libreria necessaria all’esecuzione della web app;
- library(DT): la libreria di DT contiene la funzione datatable che produce un tabella completa di paginazione e filtro di ricerca integrati;
- source(‘path script di backend’): e necessario dire ad R dove trovare lo script di backend per renderne disponibili le funzioni di elaborazione;
- Con un po’ di immaginazione si può intuire facilmente come verrà tradotto il codice generato per il browser dalla componente ui dell’applicazione:
- Per esempio la funzione actionButton() corrisponde tag HTML <input type=”button”>, la funzione selectInput() è assimilabile a un tag <select></select>, ecc.
- Altre funzioni come fluidPage() e siderbarLayout() trovano invece corrispondenza nelle classi implementate dal noto framework BootStrap
- A datatableOutput() corrisponde invece il noto plugin dataTable della libreria JQuery
- Per quanto riguarda invece le funzioni utilizzate per la componente server notiamo fondamentalmente l’utilizzo di due funzioni principali che rispondono all’input dell’utente:
- Reactive() si attiva quando l’utente seleziona dal menu a tendina l’iniziale dell’autore e modifica dinamicamente la tabella con in nomi degli autori
- ObserveEvent() si attiva quando con il button Search, il server riceve in input il nome dell’autore che abbiamo inserito nel form e genera un elenco delle opere disponibili e un elenco dei file epub se presenti.
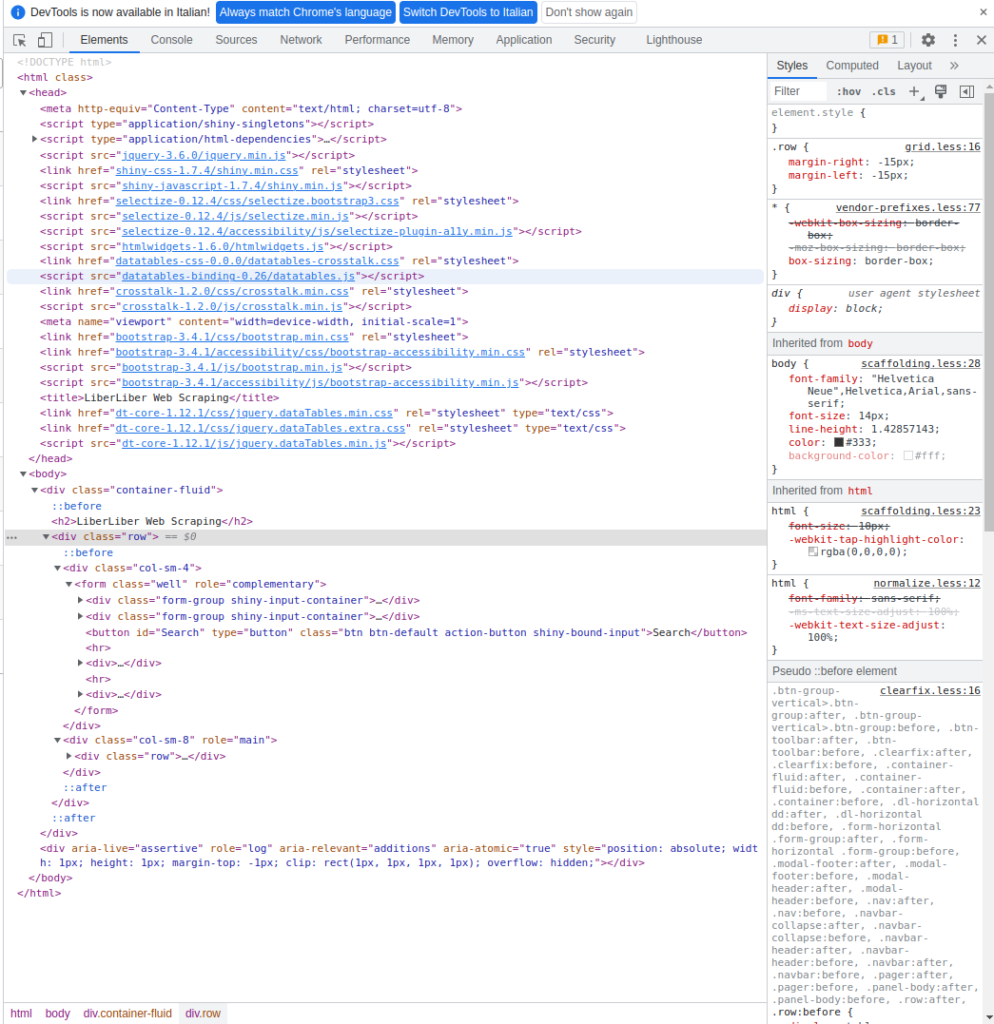
Una semplice inspection del codice della pagina visualizzata dal browser (tasto F12) ci mostra in effetti i reference a Bootstrap e JQuery.
Conclusioni
Nell’esempio che vi ho mostrato oggi, ho implementato una soluzione relativamente semplice per estrarre informazioni da un sito web, limitandomi ad elaborare i link presenti nelle diverse pagine.
Ho volutamente lasciato al lettore, che ha voglia di cimentarsi alcune parti da svelare: per esempio se arrivate a concludere lo script di back-end noterete che il link all’epub non è un permalink e quindi, se non erro, durante il download vi si apre anche il browser sulla pagina della donazione.
Come trovare il link diretto al posto di quello farlocco?
Oltre all’epub sul portale le opere sono disponibili anche in altri formati (es. .pdf, txt, zip, ecc.), per semplicità ho scelto un solo tipo di supporto.
R è uno dei tanti linguaggi che si presta all’analisi dei dati testuali, lo stesso tipo di problema lo avremmo potuto affrontare con Python o con PHP scrivendo a mio avviso qualche riga in più di codice.
Se fate una ricerca in rete, e avete voglia di provare qualcosa di più potente, vedrete che per lo scraping esistono un intero universo di framework opersource basati per lo più su Python (es. Scrapy).


